Throw the book at him, Part 3
Back in Part 1 we talked about the idea of using a large collection of books as a source of cribs to plug into cipher texts. Can we use a large collection of books, such as Project Gutenberg, to find pieces of real solutions to the ciphers?
I created an experiment to explore this idea. First, the 408 and 340 ciphers are broken down into chunks. Each chunk of cipher text must have some minimum number of repeated symbols. Chunks that have many repeated symbols are difficult to find solutions for, since the solutions must have repeated letters in the exact same locations. If we pick chunks that have too few repeated symbols, then there are way too many solutions that will fit.
Then, a program processes all of Project Gutenberg’s books. Each book is converted into a stream of uppercase text, with all punctuation and numbers removed. For example, here is what the beginning of A Tale of Two Cities looks like when it is converted:
ITWASTHEBESTOFTIMESITWASTHEWORSTOFTIMESITWASTHEAGEOFWISDOM
ITWASTHEAGEOFFOOLISHNESSITWASTHEEPOCHOFBELIEFITWASTHEEPOCH
OFINCREDULITYITWASTHESEASONOFLIGHTITWASTHESEASONOFDARKNESS
The program then looks through all of the text from the books to find pieces that fit into the chunks we created from the cipher texts. In total, the program examined over eleven billion characters of text.
It is a bit like finding a needle in a haystack, since the chances are low of finding a long piece of text that exactly matches the real solution. Actually, it’s a bit worse than finding a needle in a haystack: It is more like finding a needle in a needle stack, because very many pieces of text can fit into a chunk of cipher text. You have to come up with a way to figure out which needle is the one you’re really looking for.
For example, take a look at this 46-character chunk of cipher text from the 408-character cipher:
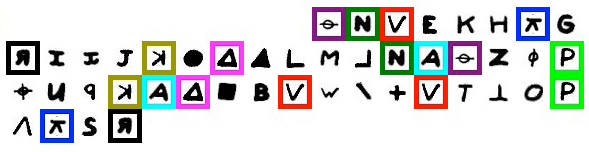
The repeated symbols are highlighted in different colors. The symbol 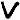 occurs three times. And each of the following symbols occurs twice:
occurs three times. And each of the following symbols occurs twice:  ,
,  ,
, 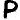 ,
, 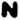 ,
, 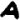 ,
,  ,
,  , and
, and 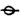 .
.
Our attempted solution must also have repeated letters at those highlighted positions. We already know the real solution to the 408-character cipher. Here’s the piece of the real solution that fits into the above chunk of cipher text:

The program scanned over eleven billion characters of text from over 31,000 books, but only found one piece of text that fits into the same chunk:

That text comes from a book called “The life of Edward, Earl of Clarendon, lord high chancellor of England: Volume 2”:
The King was not of a mould to resist plain speaking like this, and when not supported by the presence of those who made him their tool and instrument, he seldom managed to make way against the vehemence of Clarendon’s rebukes.

Edward, Earl of Clarendon. Not the Zodiac Killer.
So, only one piece of text, from a vast collection of eleven billion pieces of text, fit into this chunk of cipher text. A one in eleven billion chance seems to suggest some significance. But don’t be fooled by this. Just because this rare event occurred, doesn’t mean it is anything more than a simple coincidence. If we didn’t already know the real solution to the 408, how do we know that this chunk of old and obscure text isn’t the correct solution? Well, let’s look at what happens to the rest of the cipher when we plug in the text:

You can easily see that the rest of the cipher turns into gibberish. There isn’t much you can do with text like “GGAKRNWAEOEI” and “HMRWTMA”. Nevertheless, passionate enthusiasts won’t stop when they create similar gibberish phrases from the 340-character cipher’s mysterious symbols, and will instead labor endlessly to discover some hidden meaning in the random noise. For example, “HMRWTMA” can be re-arranged to spell out “Hmm, wart!” And “GGAKRNWAEOEI” can be scrambled to read “Gain weak ogre” or “Woke in garage”. The enterprising amateur may then lay out a fictionalized narrative involving a wart-covered killer, describing victims waking in his garage. This is an oft-travelled path to ruin. Even Robert Graysmith fell prey to this unfortunate path when he claimed to solve the 340 cipher in his book which popularized the Zodiac Killer case.
Let’s ignore those delusions for now and return to our little experiment. Can we automatically separate the bad solutions from the good ones? Well, one way to do it is to measure how “English-like” the rest of the plaintext solution appears when the chunk of text is plugged in. Here’s what the partial decodings look like for the wrong solution, and the right solution:
T_A_M_AM_EG_NG_NMKAW_S___TIA_DU___
SM_IARE__YAL___NOSM_TOMAG_DA___E_N
EIESMM_TEG_IAK_H__W_S_TDRO___HNNSM
_LAR_NEGH_SMY_SOME__AOM___NISAI__E
_MD_GROK_UHNESTTOMA__W_N_ELM_NAIE_
M_GGAKRNWAEOEI__IRT___Y_TE_____M_D
ANSH_AA_EOLANDINSTRUMENTHESELDOMMA
NAGEDTOMAKEWAYAGAINSTE_A____NS__RS
LEOS_N_T__M_DAOMAG___K___OH_W_TDTM
_GYN_A_W_____IS_KAM_S_DN_Y_DT_OEA_
IU_M_TN_D__E_EUN____OO__NAG_____S_
M_MYA__HMRWTMA_K_AN_TTKR__NISONARE
I_I_E_IL_IN_PE_PLEBE_A___ITI_SO___
HF_NITI__ORE___THAN_ILLIN_WI___A_E
INTHEF_RRE_TBE_A__E_A_ISTH___ATDAN
_ERT_EANA_ALO_ALLT__ILL___ETHIN__I
_ES_ETHE_OATTHRILLI__E_P_REN_EITI_
E_ENBETTERTHAN__TTI___O_RR_____F_W
ITHA_IR_THEBESTPARTOFITIATHAEWHENI
DIEIWILLBEREBORNINPARA_I____DA__TH
EIHA_E_I__E_WILLBE___E___LA_E_IWIL
_NOT_I_E_____NA_EBE_A_SE_O_WI_LTR_
TO_L_ID_W__R_TOP____LL__TIN_____A_
E_FOR__AFTERLI_E_BE_RIET__ETHHPITI
Zkdecrypto, the powerful cipher-solving tool, calculates a score by measuring small chunks of text (from two to five letters long) against a large sample of real English text. Text that resembles real English will score higher than gibberish text.
When we plug in our “Earl of Clarendon” solution, the rest of the plain text that appears results in a score of 1982. But the plain text that appears when we plug in the real solution results in a much higher score of 3585. Why?
It’s because the correct solution results in the appearance of more chunks of real words in the rest of the plain text. For example, Zkdecrypto finds these five-letter chunks, which all occur frequently in English: INTHE, WITHA, AFTER, ETHIN, EINTH, ERTHA, TERTH, ETTER, NTHEF, WILLB, ILLBE, RTHAN, BETTE, TTERT, ILLIN, RILLI, TERLI, OATTH, HRILL, FTERL, ENBET, ATTHR, NBETT, PLEBE, THRIL, ATDAN, HEIHA, TTHRI, and THEIH. On the other hand, the incorrect solution produces very few five-letter chunks of real English in the rest of the plain text: ONARE, ISONA, SONAR, and NISON.
It’s important to note that Zkdecrypto can solve the 408-character cipher all by itself, because it is very good at discovering keys that produce high-scoring plain text. The 408 cipher is a simple substitution cipher, and even though it has a few spelling and encipherment mistakes, it still falls quickly to Zkdecrypto’s powerful search.
Did our book-scanning experiment find any solutions to the 408 that come close to being correct? Yes. Well, sort of. The most exact match happened when finding text to fit this bit of cipher text in the first row:


That chunk of cipher text, despite containing several repeated symbols, is not highly constrained. Thus, the program found many thousands of pieces of text that fit there. Here is one example, found in Punch, or The London Charivari, Vol. 62, January 20, 1872:
But of all places, posts, offices, appointments, and dignities within the reach of an Englishman, the one which excites in us the least desire is that of “Examiner of Plays.”

The correct answer, “LIKEKILLINGPEOPL”, is buried under many thousands of possible solutions. If we use our Zkdecrypto score to sort the results from best to worst, we find that the correct answer is in the 334th spot. Not that great. That chunk of cipher text is simply too small, allowing for too many solutions.
Examining the rest of Project Gutenberg, the program did not find any more exact matches to the real solution to the 408. However, it did manage to find some longer pieces of text that are very close to the real solution:

A match comes from The Book of the Thousand Nights and a Night, Volume 1, by Richard F. Burton:
…for assuredly if he cured me by a something held in my hand, he can kill me by a something given me to smell. Then asked King Yunan…

The known solution is:
…to kill something gives me the most thrilling experence…

Only about a quarter of the symbols from the 1001 Nights solution are wrong. Just as before, many thousands of pieces of text were found that fit into this chunk of cipher text. But when we sort them by Zkdecrypto scores, the 1001 Nights solution appears as the 4th highest-scoring solution. This stack of needles is more promising since we are much closer to the real solution and have fewer needles to exclude before reaching a good one.
So, we’ve shown that cribs and zkdecrypto’s scoring technique can be useful. And, frankly, it’s easier to just use zkdecrypto on the 408 cipher since it is very good at finding its real solution, without needing to search through a large body of text. However, I think it’s useful to experiment with cribs because it changes the landscape of the search for solutions. At the very least, It is another tool at our disposal for attacking unsolved ciphers. It also demonstrates that just because you found a long phrase that fits somewhere in a cipher text, it doesn’t mean it’s correct.
But can it help with the unsolved 340-character cipher? The search experiment found many pieces of text that fit into various chunks of the 340. Here’s an example of a chunk of the 340 that has many repeated symbols, making it hard to find text that fits. But the search found a single piece of text that does:


The text is from Fruits of Queensland, Australia, by Albert Benson, published in 1914:
In addition to its value as a fruit, the mango forms a handsome ornamental tree, and one that provides a good shade for stock.
As before, this snippet was the only text, from over eleven billion pieces tested, that fit into this chunk of cipher text. Also as before, this doesn’t mean it’s correct, since the rest of the plaintext turns into junk.
During its search, the program retained over 635,000 chunks of plaintext that fit into various places in the 340’s cipher text. Could any of them be correct or close to correct? Some of them produce high Zkdecrypto scores. Here’s an example:


It is from Captain Cook’s Journal During the First Voyage Round the World, by James Cook:
…to examine all Ships that pass and repass these Straits. We now first heard the agreeable news of His Majesty’s Sloop…
Many high scoring solutions were found by the program. But is this all just a pointless parlor trick? The 340 is very likely to be something other than a simple homophonic substitution cipher. Some “twist” in its construction has thwarted us all for more than forty years. So, an approach like this that assumes the cipher is “normal” is likely to fail. But could the seed of a real solution lurk somewhere in the results? Who knows. If you want to search for yourself, download the full results here:
constraint-search-340-data.zip (16,664,537 bytes)
constraint-search-408-data.zip (11,696,987 bytes)
Here is a sample line from the raw file:
37, 237, +yBX1*:49CE>VUZ5-+|c.3zBK(Op^.fMqG2Rc, TENDEDTOSHOWFIGHTTHEYGENERALLYFLEDWHE, 15, 1.8402534E-5, {0 17} {2 23} {20 29} {19 36}, 3422.75, 92.50676
And here’s an explanation of the data format:
- 37: Length of chunk
- 237: Position of chunk. Positions start at 0.
- +yBX1*:49CE>VUZ5-+|c.3zBK(Op^.fMqG2Rc: Transcription of cipher text chunk
- TENDEDTOSHOWFIGHTTHEYGENERALLYFLEDWHE: Plain text chunk
- 15: Number of unique letters in the plain text
- 1.8402534E-5: Constraint difficulty. Lower values reflect higher difficulty (due to larger numbers of repeated symbols)
- {0 17} {2 23} {20 29} {19 36}: Positions of repeated symbols, grouped into pairs
- In the data for the 408, another value appears before the Zkdecrypto score, representing the proportion of characters in the solution that match the real known solution.
- 3422.75: Zkdecrypto score
- 92.50676: Zkdecrypto score divided by chunk length
The book is still open on the 340.