Zodiac at the ACL 2013 conference
The Association for Computational Linguistics held its 2013 conference in Bulgaria earlier this month. Computational Linguistics is the study of how to apply computer science to problems involving language and speech. It’s a very broad subject, which also includes studies of how to decipher codes and cryptograms.
An interesting paper to emerge from this conference is “Beam Search for Solving Substitution Ciphers”, authored by some folks from RWTH Aachen University in Germany. They claim the technique in their paper can very quickly crack substitution ciphers with very small decipherment error. They also apply the technique to the Zodiac Killer’s 408-character cryptogram.
The paper has this claim:
Unlike the previous state-of-the-art approach that uses additional word lists to evaluate possible decipherments, our approach only uses a letter-based 6-gram language model.”
They must not be aware of other effective n-gram based hillclimbers such as zkdecrypto and CryptoCrack. This is probably because those tools are seldom cited in other academic papers, so researchers tend to overlook them.
(Ravi and Knight, 2011a) report the first automatic decipherment of the Zodiac-408 cipher. They use a combination of a 3-gram language model and a word dictionary.
From the referenced paper:
The new method can be applied on more complex substitution ciphers and we demonstrate its utility by cracking the famous Zodiac-408 cipher in a fully automated fashion, which has never been done before.
An early version of zkdecrypto was able to automatically and fully decipher the 408 back in December 2006. My 2008 paper descibes an automatic decipherment of enough of the 408 to easily derive the complete solution. And there must be other automatic solvers out there that could have handled the job. The 408 is not a difficult cryptogram to solve using statistical methods, because there are enough clues in it to give codebreakers leverage.
This small oversight notwithstanding, the new approach described in the ACL 2013 paper is interesting. Beam search is a variation of breadth-first search. A breadth-first search starts with an initial key, and then explores every possible change to it. This is not practical, due to the astronomical number of possible keys. Beam search fixes that by “pruning out” the low-scoring possibilities, so it only has to explore the ones it thinks are worth the trouble. The scores are based on n-gram statistics, weeding out solutions that don’t resemble normal English.
This seems to be a bit more systematic than other hillclimbers such as zkdecrypto that use a randomized search that continually “perturbs” the key, exploring the higher-scoring modifications. It’s unclear how well beam search stacks up against zkdecrypto, since zkdecrypto is already shown to be very fast and effective. The paper does not mention the unsolved 340 at all. The 340 will very likely not succumb to yet another approach that assumes a conventional construction, but I’m still curious what happened when they ran the algorithm against it.
Also in the conference, Kevin Knight gave a tutorial entitled “Decipherment”, in which he discussed the basics of codebreaking, classic historical ciphers, and famous unsolved codes:

Click here to view the slides from his tutorial
Highlights:
- An interesting angle Knight presents is that translating from a foreign language is a lot like dealing with a cipher, where you substitute words with other words.
- This slide made me think of zkdecrypto:

Random restarts are used in zkdecrypto to great effect, helping the hillclimbing search avoid getting stuck on hills that are too small. - Knight reviews some recent historical decipherments: Jefferson cipher, a Civil War cryptogram, German Naval Enigma, and Knight’s own work cracking the Copiale cipher.
- One of the keys to cracking the Copiale cipher was to cluster the cipher alphabet based on similar contexts (i.e., certain symbols tend to be preceded by or followed by specific symbols). The clusters were determined with a very useful “cosine similarity” measurement, which I implemented in CryptoScope. If you switch to the 408 there, and click the “Letter Contacts” button, you’ll see a Cosine similarities section under the contacts grid. It shows how all the real homophones tend to cluster at the top of the list.
- I’d assumed that much of the Copiale breakthroughs were discovered via computer, but apparently a lot of pencil and paper work was needed:

- The NSA recently declassified a 1979 paper by Mary D’Imperio about applying modern statistical techniques to the Voynich Manuscript. See also: D’Imperio’s The Voynich Manuscript: An Elegant Enigma.
- The NSA also recently declassified 4,400 pages of its newsletter, “Cryptolog“. Despite containing numerous redactions, it has some interesting articles on many topics, including the Voynich Manuscript.
- Knight talked about his 2011 paper with Ravi in which their method produced a very accurate decipherment of the Zodiac’s 408 cipher.
- He also talked about the unsolved Zodiac 340, and how it has no obvious reading order bias based on analyzing bigrams in several directions:
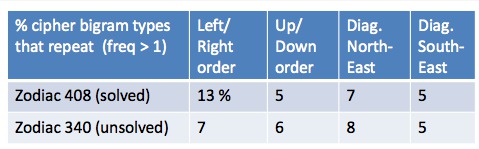
There you can see the 408 has a preference for left/right order, since it results in a spike of repeating bigrams. So, the 340 “could be nonsense, or maybe bigrams are smoothed out via more careful substitutions.”
Sounds like it was a fascinating conference. Maybe I can attend the next one. Meanwhile, have a look at the NSA’s upcoming 2013 Cryptologic History Symposium. Among the speakers will be Klaus Schmeh and David Kahn. And I’ve heard that Elonka Dunin will be there. Looks like a unique learning opportunity!
Is there a way to find out if a name fits the cipher and then work back from there to solve the characters in the cipher? I mean what if the right name, or names, could help unlock the cipher? Is there a way to test a name for that? Is so, please contact me: mysterri at gmail dot com.
Theoretically, that could work if you happen to insert the name in the right format in the right place, resulting in partial decipherment that scores higher than other partial decipherments. But a problem is that so many names can fit in numerous locations of the 340. And also, we don’t yet know how the 340 is constructed. So even if the correct name is placed in the right spot, we don’t yet know what the correct manipulations of the cipher text are that would result in a fair comparison against other name insertion attempts.